My First Outage: The Bad of Storing Logs in Database
Software can running 24/7 but what if you have a bad time because suddenly your system is down and you have no idea what's going on?

Hi, I am a cat lover and software engineer from Malang, mostly doing PHP and stuff. Software Engineer Live in Malang, Indonesia Visit my resume and portfolios at didiktrisusanto.dev See you, folks!
This outage was one of my memorable events as a software engineer because of some reasons:
My first job at product based startup
I was a new joiner
I didn't have production access and had limited knowledge about how the current system was running
Infrastructure Schema
To give you more context on what I've been dealing with, I'll give you some information about how the services were running.
We have 2 main sites that face our users directly. One site (main store) is a monolith service running on a single VM and the other sites are API-based service that serves the mobile app and the dashboard. All sites are using the same database which is divided into
Master DB: used to write queries (read/write)
Replica DB: used to read queries (read)
High-level design should be like this
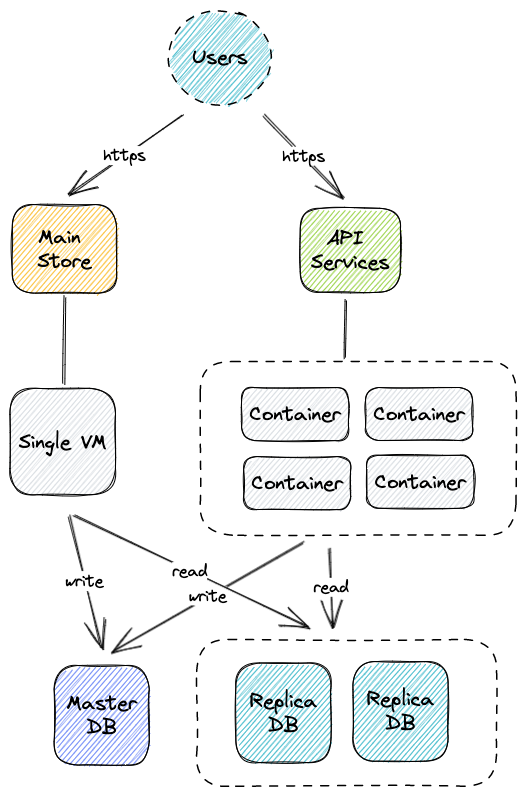
The main store codebase is quite old (>5 years) and API services are quite recent and have more proper codes. All of the services are running in the cloud infrastructure with very little documentation.
The Beginning
It was Friday night around 9 pm (Jakarta Time) I was about to close my laptop and get ready to have some rest. Suddenly got a notification in my work email that my senior teammate sent me production credentials. I already have my cloud credentials but that was only for a couple of services unrelated to the VMs access. I wonder why.
Minutes later, my CTO called me to inform our main store was inaccessible to our users and he asked me to check if there was a database failure. Imagine at that moment we had no proper on-call procedure and our on-call person was unavailable at the moment yet I had no visibility of what was going on.
My first initiative was:
Checked database usage, no anomalies, no high CPU load
Checked our main store was legit unaccessible with 500 errors. I checked our API service which uses the same database and was running normally.
Checked the latest deployment no migration or related database changes
No clues about what's the error was.
Debugging
Seems our users got furious and that made our CEO create a war room between him, me, one of the senior AM, and the CTO to investigate what's the issue and how to solve it. Turned out it was already 1 hour since the first incident without a single engineer to solve the issue.
CTO assumed there was database failure and he started to do failover on the master database but no luck. Meanwhile, I need to figure out how to find some error logs related to this issue and find the root cause. Because if we have database failure, our APIs should not be working either.
There was no documentation for this so I need to figure it by myself.
The main store is a monolith web application running in a single large VM. I might find something there especially somewhere in /var/log/nginx/error_log or /var/log/nginx/access_log which is usually been used to log web applications. I quickly logged in to the production VM and search the logs.
Voila...
I found the error logs and they stated that one of our table-named log already has a maximum integer value on the primary key and couldn't write new rows anymore. I did a quick read of our main store codebase and found many information has been written into log table. So every time user is accessing our main store, it will create multiple rows of information persisted on that table.
By definition, log table looks like this
log (
log_id INT AUTO_INCREMENT PRIMARY KEY
user_id INT
log_message TEXT
...
)
After many years of serving the application with massive rows of logs, it finally log_id reached the maximum value which is 2147483647. I told my CTO about this finding and now the root cause has been found.
At this moment also we realized in some endpoints of our APIs might be getting error because we were sure it also has some action to write a message to the log table. That's explained why when I checked some APIs it was fine because it was just lucky that APIs not writing messages to log.
Deleting Massive Rows
Finding the root cause made everything clear about how to solve this. One simple solution was to truncate the log table so later it can be written again. At this moment we consider that the data in the log is not necessary anymore and we can safely delete it.
We tried to run the truncate script against our log table
TRUNCATE TABLE log;
It just hung up and failed.
We tried with several attempts but still failed. How about deleting per 1 million rows as a chunk? Maybe truncating the whole table was too much.
DELETE FROM log ORDER BY log.id LIMIT 1000000
We wait and still hung up then failed.
We kept trying to delete the log desperately. Made the chunk size smaller become 10000 and even 1000 yet couldn't get the expected result. The table was kind of locked because we performed deletion meanwhile there were still many write actions in log table that came from our main store. We didn't have a way how to stop because we even didn't have maintenance mode to prevent users from accessing our service.
The war room became intense. It's almost 3 hours of downtime now with none of the solutions working and it's very unacceptable. User complaints kept increasing, and they lost money because no one could transact during the outage.
The Light
I have no clue about how the delete or truncate mechanism in MySQL is under the hood. I tried to think if this can be solved at the application level. I was thinking if it was more simple rather than solving by database level. Then I remembered that we were using PHP Framework, and the log should be defined under model or active record.
I traced the log script in the main store codebase and found it was controlled by a model. The model was based on Doctrine and looked like this
<?php
class Log extends sfDoctrineRecord
{
public function setTableDefinition()
{
$this->setTableName("log");
// rest of the schema definitions
}
}
Traced in the API codebase and it wasn't controlled by the model but it was called by a query builder. It was something like this
<?php
use Illuminate\Support\Facades\DB;
DB::table('log')->insert([
'log_message' => $message,
'log_date' => date('Y-m-d H:i:s')
]);
As you can see both codes were referring to the same log table name. Suddenly I got an idea.
How about we create a new table log with the same schema as old
logtable, let's saylog_new.Then we changed the table definition on the codes so all write statements will go to a new table and we can safely truncate or delete the oldlogtable.
My CTO agreed with the idea and I created a PR to change the code meanwhile CTO manually created the new table (unfortunately, we have no proper migration script at that moment so it has to be done manually). Pull Request merged and deployed within minutes, then service back to normal. All message logs have deviated to the new table.
Finally a sigh of relief in the war room after 3+ hours of outage. The intensity was cooling down and the headache was suddenly gone. We were never expecting this little issue could break down almost all the service and yet the solution is very simple.
Post Morterm
3+ hours of downtime is unacceptable. The user was losing money, customer become unhappy or maybe their trust was decreased and decided to not use our service anymore. We were a little bit lucky because it happened outside working hours and wasn't in peak time.
After this outage, we did an immediate assessment of how we stored the log. The reason why it was stored in a database was that a long time ago, not every developer has access to the infra so storing debug messages or information in the database was the easier one since everyone got database access in the dev environment and production (read-only). We didn't calculate if our table is full then our service will be down.
Our next action plan was:
Prevent log into the database and use proper logging instead. We chose AWS Cloudwatch at that time.
Remove unnecessary logging action, only log for the necessary
Delete the old
logtable
Lesson Learned
Cutting the edge during the development of software sometimes is cheap and easy to get immediate results but it will create tech debt. This kind of tech debt is like a bomb that could explode anytime if you're not tackling it properly, especially with database usage.
Usually, many bottlenecks came from database issues like poorly written queries, not using the index properly, or even not properly designing the schema could cause many unnecessary query calls. It has to be maintained and monitored over time. So always plan before building the software. It's a good habit for us as a software engineer.




